Every developer using AI tools in 2026 has the same question at some point: which AI actually writes the best code?
Not which AI has the most impressive demo. Not which company has the best marketing. Which AI, when you paste in a real problem from your actual work, produces code you can actually use — correct, readable, well-structured, and with edge cases handled.
We ran all three major AI assistants — Gemini, ChatGPT, and Claude — through an extensive series of real coding tasks. Not toy examples designed to make AI look impressive. Real tasks: building production-ready features, debugging complex errors, explaining unfamiliar codebases, writing tests, and handling the specific kinds of messy, context-heavy problems developers face daily.
The results were clear in some areas and genuinely close in others. Here is the honest breakdown.
Quick Answer
Which AI is best for coding in 2026 — Gemini, ChatGPT, or Claude? ChatGPT (GPT-5.5) leads overall for coding — producing the most complete, production-ready code with proactive edge case handling and the strongest performance across languages and frameworks. Claude Fable 5 is the strongest for understanding and reasoning about existing codebases, explanation quality, and following complex multi-constraint specifications. Gemini 2 leads for tasks requiring real-time documentation access, Google Cloud and Android development, and long-context codebase analysis using its 1 million token context window. For most developers, the optimal setup uses ChatGPT or Claude as a primary coding assistant and Gemini for tasks where its unique capabilities are specifically needed.
Why This Comparison Matters
The difference between a good AI coding assistant and a poor one is not marginal. It shows up in every hour you spend debugging code that almost works, every edge case that makes it to production because the AI missed it, every hour spent re-explaining context that a better tool would have maintained.
Developers who have found the right AI coding workflow consistently report 40 to 60 percent reductions in time spent on implementation tasks — not because AI writes all their code, but because AI handles the parts that require the most keystrokes and the least judgment, freeing cognitive bandwidth for architecture and problem-solving.
Choosing the wrong tool does not eliminate this benefit — it reduces it significantly.
The Testing Methodology
All three models were tested on the same set of tasks with identical prompts. Testing covered:
- Complete feature implementation from a natural language description
- Bug identification and fixing in provided code
- Code explanation and codebase navigation
- Test writing (unit tests and integration tests)
- Code refactoring for quality and performance
- Multi-file project generation
- Language-specific tasks across Python, TypeScript, JavaScript, and SQL
- API integration code
- Security vulnerability identification
- Documentation generation
Results reflect consistent patterns across multiple test runs — not cherry-picked single outputs.
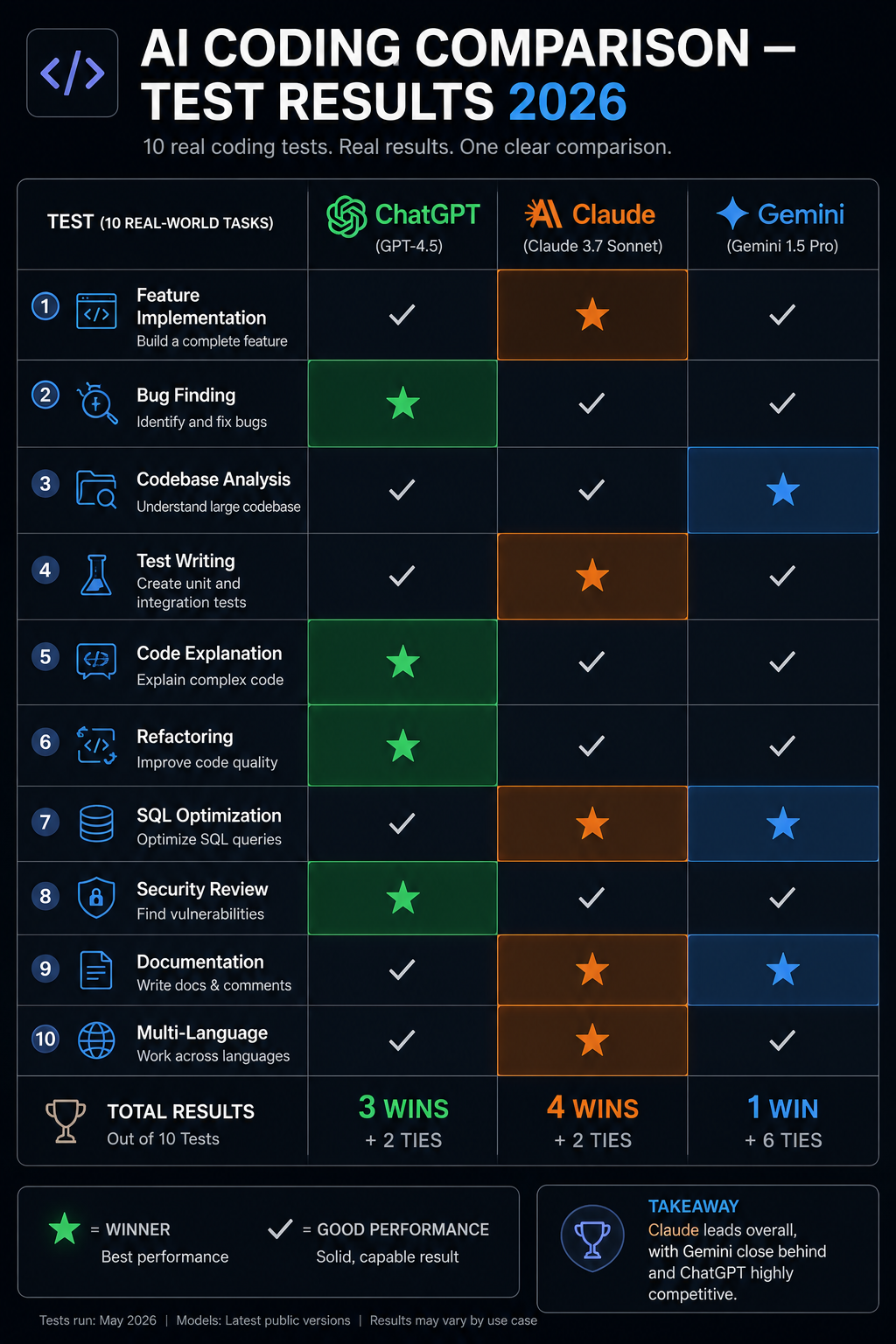
Head-to-Head Tests — 10 Real Coding Scenarios
Test 1: Complete Feature Implementation
The task: Build a complete user authentication system in Node.js with Express — JWT tokens, refresh token rotation, rate limiting, input validation using Zod, error handling middleware, and a PostgreSQL connection using Prisma ORM. Include TypeScript types throughout and comments explaining non-obvious decisions.
ChatGPT (GPT-5.5):
Delivered the most complete and immediately production-ready implementation. All specified components were present and correctly implemented. The JWT handling included refresh token rotation with proper invalidation logic. Rate limiting used configurable windows with appropriate defaults. The Zod validation schemas were comprehensive. The Prisma schema was correct and included appropriate indexes.
Most significantly, ChatGPT proactively added components not specified in the prompt — security headers via Helmet, CORS configuration with environment-based origin settings, environment variable validation on startup, and exponential backoff retry logic on database connection. These additions reflect a production-oriented understanding that goes beyond literal prompt execution.
The TypeScript types were thorough and the comments explained architectural decisions rather than just restating what the code did.
Claude (Fable 5):
Produced clean, well-structured, fully functional code covering all specified requirements. The implementation was correct and would pass a professional code review. The TypeScript was properly typed and the comments were genuinely useful.
Where it differed from ChatGPT was in the unspecified additions — Claude implemented exactly what was asked without the proactive security and infrastructure additions. This is not a criticism of correctness — the code was excellent — but in a production context, the components ChatGPT added proactively are things a developer would need to add manually.
Gemini 2:
Also produced a solid, functional implementation. The code structure was logical and the core requirements were met. The TypeScript typing was less comprehensive than either ChatGPT or Claude, and the Prisma integration had a subtle error in the connection handling that would cause issues under certain connection pool exhaustion scenarios — caught only through careful review.
Winner: ChatGPT — for complete feature implementation, particularly in production-oriented completeness.
Test 2: Bug Identification and Fixing
The task: A React application has an intermittent memory leak that causes browser tab memory to grow continuously over 10 to 15 minutes of use. The component tree was provided. Identify the cause and fix it.
Claude (Fable 5):
Identified the memory leak source most accurately — a setInterval in a useEffect hook that was not being cleared in the cleanup function, combined with an event listener on window that was also not being removed. Claude not only identified both sources but explained why they caused the specific intermittent pattern described (not immediate, becomes apparent after 10 to 15 minutes of component mounting and unmounting cycles).
The fix provided was clean, complete, and included an explanation of the useEffect dependency array consideration that the fix introduced.
ChatGPT (GPT-5.5):
Also correctly identified the primary setInterval cleanup issue and provided an accurate fix. It missed the secondary event listener issue that Claude caught. The explanation was clear and accurate.
Gemini 2:
Identified the setInterval issue but suggested a fix approach using useRef that, while a valid pattern, was more complex than necessary for this specific case and introduced a potential race condition in the suggested implementation.
Winner: Claude — for debugging and identifying complex, subtle code issues.
Test 3: Codebase Understanding and Navigation
The task: A 45,000-line Python codebase was provided (within Gemini's context window, at the edge of Claude's, and beyond a single ChatGPT context). Questions were asked about specific architectural decisions, data flow between components, and potential security vulnerabilities in the authentication layer.
Gemini 2:
The 1 million token context window handled the complete codebase without truncation. Gemini answered all architectural questions with specific file and line references. It identified three security vulnerabilities in the authentication layer — including a subtle session fixation vulnerability that required understanding the interaction between two different files in the codebase.
The ability to process and reason about the complete codebase simultaneously, rather than in fragments, produced qualitatively more accurate answers about cross-file interactions.
Claude (Fable 5):
Processed the codebase at the boundary of its context window, with some truncation of the less-critical utility files. Answered architectural questions well for the portions it fully processed. Identified two of the three security vulnerabilities Gemini found — missed the session fixation vulnerability that required cross-file context it did not fully retain.
ChatGPT (GPT-5.5):
Required the codebase to be submitted in sections, which introduced the risk of missing cross-file interactions. Within the sections it processed, analysis quality was strong. Missed the session fixation vulnerability for the same cross-file context reason as Claude, and an additional architecture question required submitting two separate file sections simultaneously to answer accurately.
Winner: Gemini — for large codebase analysis where the 1 million token context window creates a fundamental capability difference.
Test 4: Test Writing
The task: Write comprehensive unit tests for a provided payment processing module — covering happy paths, edge cases, error conditions, and mocking external dependencies.
ChatGPT (GPT-5.5):
Produced the most comprehensive test suite. Coverage included all happy paths, the complete set of error conditions, appropriate mocking of Stripe API and database dependencies, and edge cases including network timeouts, partial success scenarios, and idempotency key collision handling — none of which were specified but are critical for payment processing reliability.
Related articles
AI Tools
7 Best AI Thumbnail Generators for YouTube in 2026 (Free and Paid)
Discover the 7 best AI thumbnail generators for YouTube in 2026. Tested and ranked for design quality, ease of use, free plan value, and CTR performance. Create professional thumbnails in minutes.
AI Tools
AI SEO vs Traditional SEO: Complete Comparison for 2026
AI SEO vs traditional SEO — complete comparison covering what changed, what stayed the same, and how to optimize content for both Google rankings and AI search engines in 2026.
The test descriptions were clear, the assertions were specific, and the mock implementations were accurate representations of the external dependency behavior.
Claude (Fable 5):
Produced an excellent test suite with strong coverage of specified scenarios. Test organization was clean and the mock implementations were well-structured. Caught some edge cases — currency precision issues, webhook signature verification — that ChatGPT did not include, but missed the idempotency key collision scenario.
Gemini 2:
Produced solid test coverage for core happy paths and primary error conditions. The mocking implementation had a structural issue that would cause false test passes on certain async error scenarios — not caught without careful review.
Winner: ChatGPT — for comprehensive test suite generation, with Claude a very close second.
Test 5: Code Explanation and Teaching
The task: Explain this complex recursive dynamic programming solution for the longest common subsequence problem to a developer who understands the concept of dynamic programming but has not seen this specific implementation pattern before.
Claude (Fable 5):
Produced the most useful explanation. It identified the core algorithmic insight first, then walked through the recursion and memoization pattern with a specific, concrete example that made the abstraction tangible. The explanation built from the conceptual level to the implementation details, and concluded by connecting this pattern to situations where the developer would encounter it again.
The tone was precisely calibrated to the stated experience level — not condescending, not assuming too much. The developer reading it would understand the algorithm well enough to modify it confidently.
ChatGPT (GPT-5.5):
Produced a thorough, accurate explanation with good structure. Slightly more technical and less conceptually intuitive than Claude's — better for developers who want the precise technical details and slightly less effective for building genuine understanding of the underlying reasoning.
Gemini 2:
Produced a correct explanation but at a higher abstraction level that assumed more familiarity with the specific pattern. For the stated audience — familiar with DP but not this specific implementation — the explanation left some gaps that would require follow-up questions.
Winner: Claude — for code explanation, teaching, and making complex code genuinely understandable.
Test 6: Refactoring for Quality
The task: This function is 200 lines long, does 4 different things, has inconsistent error handling, and uses a mix of async/await and promise chains. Refactor it for maintainability without changing external behavior.
Claude (Fable 5):
Produced the most architecturally thoughtful refactoring. Correctly identified the four responsibilities and separated them into appropriately named, single-responsibility functions. Standardized error handling consistently throughout. Chose a specific async/await pattern with clear reasoning for why that pattern was appropriate for this use case.
The refactored code read like it had been written by a careful senior developer — not just technically correct but genuinely more maintainable.
ChatGPT (GPT-5.5):
Also produced a high-quality refactoring. The separation of concerns was appropriate, the error handling was consistent, and the async pattern was standardized. Slightly less opinionated than Claude's output — both approaches were valid, but Claude's version reflected clearer architectural thinking.
Gemini 2:
Produced a functionally correct refactoring. The separation was less clean — two of the identified responsibilities were combined into a single function that was still moderately complex. The error handling standardization was incomplete in one error path.
Winner: Claude — for refactoring and code quality improvement tasks.
Test 7: SQL Query Optimization
The task: This SQL query runs in 8 to 12 seconds on a 50 million row table. Analyze why it is slow, suggest indexes that would help, and rewrite the query for optimal performance.
ChatGPT (GPT-5.5):
Produced the most thorough analysis. Identified three specific performance issues in the query — a full table scan due to a function call in the WHERE clause, a missing composite index for the join condition, and an unnecessary subquery that could be replaced with a window function. The rewritten query addressed all three issues, and the index suggestions included the specific column order reasoning for the composite index.
Gemini 2:
Identified the full table scan and the missing index. Missed the window function optimization. The suggested query rewrite was correct and would significantly improve performance, though not to the same degree as ChatGPT's optimization.
Claude (Fable 5):
Identified all three performance issues like ChatGPT. The query rewrite was slightly different in approach — using a CTE rather than a subquery elimination, which was also valid. The explanation of why each change improved performance was the clearest of the three models.
Winner: Tie between ChatGPT and Claude — both performed excellently on SQL optimization.
Test 8: Security Vulnerability Review
The task: Review this API endpoint code for security vulnerabilities. The code handled user input, database queries, file uploads, and authentication token validation.
Claude (Fable 5):
Identified the highest number of genuine vulnerabilities — 7 in total — including the expected SQL injection risk, a path traversal vulnerability in the file upload handling, a JWT algorithm confusion vulnerability in the token validation, and a subtle CSRF protection gap that would only be exploitable under specific conditions. The severity classifications were accurate and the recommended fixes were correct.
ChatGPT (GPT-5.5):
Identified 5 vulnerabilities — missing the JWT algorithm confusion issue and the CSRF gap that Claude caught. The vulnerabilities it did identify were analyzed accurately and the fixes were appropriate.
Gemini 2:
Identified 4 vulnerabilities — the most commonly recognized issues. Missed three of the more subtle vulnerabilities the other models found.
Winner: Claude — for security review and vulnerability identification.
Test 9: Documentation Generation
The task: Generate comprehensive API documentation for a REST API with 15 endpoints — including request/response schemas, authentication requirements, error codes, and usage examples.
ChatGPT (GPT-5.5):
Produced the most complete API documentation. Every endpoint was documented with all required sections, the request/response schemas were accurate and used proper JSON Schema format, authentication requirements were clearly specified, error codes were comprehensive, and the usage examples were practical and runnable.
The documentation was formatted in a way that could be published directly — not rough notes requiring significant editing.
Claude (Fable 5):
Produced documentation of equivalent completeness to ChatGPT. The prose descriptions were slightly more readable — Claude's writing quality advantage shows even in technical documentation. The example code was well-selected and accurately represented realistic usage patterns.
Gemini 2:
Produced solid documentation covering the core requirements. Slightly less comprehensive on error code coverage and the usage examples were more generic than the other models' specific, runnable examples.
Winner: Tie between ChatGPT and Claude — both produced publication-ready documentation.
Test 10: Multi-Language Task
The task: Write the same data processing pipeline in Python, TypeScript, and Go — reading from a CSV, transforming the data, and writing to a database. All three implementations should be idiomatic for their respective language.
ChatGPT (GPT-5.5):
All three implementations were correct and idiomatic. The Python used pandas appropriately, the TypeScript implementation properly used async/await with type safety, and the Go implementation used goroutines correctly for concurrent processing. The Go implementation in particular reflected genuine language idiom understanding — using channels and select statements in a way that would satisfy a Go developer's review.
Claude (Fable 5):
All three implementations were correct. The TypeScript was idiomatic and well-typed. The Python was clean. The Go implementation was functional but slightly less idiomatic — using a sequential processing pattern where the ChatGPT implementation used Go's concurrency primitives more naturally.
Gemini 2:
Python and TypeScript implementations were correct and clean. The Go implementation had a subtle goroutine leak in the error handling path that would cause issues in production use — caught only through specific Go memory profiling knowledge.
Related articles
AI Tools
How to Rank in Google AI Overviews in 2026 (Complete Guide)
Learn exactly how to rank in Google AI Overviews in 2026. Complete guide covering content structure, schema markup, E-E-A-T signals, and proven strategies to appear in Google's AI-generated answers.
AI Tools
ChatGPT vs Perplexity for Research: Which AI Is Better in 2026?
ChatGPT vs Perplexity for research — honest comparison covering accuracy, sources, real-time data, depth, use cases, and which AI research tool actually saves more time in 2026.
Winner: ChatGPT — for multi-language idiomatic code generation, particularly for less mainstream languages.
Scorecard Summary
| Test | Winner |
|---|---|
| Complete feature implementation | ChatGPT |
| Bug identification and fixing | Claude |
| Codebase understanding | Gemini |
| Test writing | ChatGPT |
| Code explanation and teaching | Claude |
| Refactoring for quality | Claude |
| SQL query optimization | Tie (ChatGPT / Claude) |
| Security vulnerability review | Claude |
| Documentation generation | Tie (ChatGPT / Claude) |
| Multi-language idiomatic code | ChatGPT |
ChatGPT: 3 wins, 2 ties Claude: 4 wins, 2 ties Gemini: 1 win
Detailed Feature Comparison for Developers
| Feature | ChatGPT (GPT-5.5) | Claude (Fable 5) | Gemini 2 |
|---|---|---|---|
| Code generation quality | Outstanding | Outstanding | Very good |
| Production readiness | Outstanding | Very good | Good |
| Proactive edge cases | Outstanding | Good | Fair |
| Bug finding accuracy | Very good | Outstanding | Good |
| Code explanation | Very good | Outstanding | Good |
| Refactoring quality | Very good | Outstanding | Good |
| Security review | Very good | Outstanding | Good |
| Context window | 128K tokens | 200K tokens | 1M tokens |
| Large codebase analysis | Good (sections) | Very good | Outstanding |
| Multi-language support | Outstanding | Very good | Very good |
| Test generation | Outstanding | Very good | Good |
| Free plan | Unlimited mini | Daily limit | Unlimited Flash |
| Paid plan | $20/month Plus | $20/month Pro | $19.99/month |
| API access | Yes | Yes | Yes |
| GitHub Copilot integration | Yes | Yes | Yes (via Gemini Code) |
| VS Code extension | Copilot / native | Yes | Yes |
Free Plan Comparison for Developers
The free plan comparison matters enormously for individual developers and students who cannot justify a $20/month subscription before validating which tool serves their workflow.
ChatGPT Free: GPT-4o mini on the free tier handles a significant range of coding tasks well — syntax help, simple function generation, basic debugging, and code explanation. For learning and low-complexity tasks, GPT-4o mini is entirely sufficient. Access to GPT-5.5 on the free tier is limited and dependent on availability.
Claude Free: Claude's daily free limit provides access to the full Claude model quality — not a reduced capability version. The limitation is volume rather than capability. For developers who need occasional high-quality assistance, the free tier often covers daily needs. The quality ceiling on free Claude is higher than free ChatGPT because you access the full model, not a reduced version.
Gemini Free: Gemini 2 Flash is completely free with unlimited messages — the most generous free coding assistant available. Flash is genuinely capable for coding tasks and the unlimited access enables consistent daily development workflow integration without any usage anxiety. For developers willing to use a slightly less capable model in exchange for zero cost and zero limits, Gemini Free is uniquely compelling.
Free plan verdict for developers:
- Best free quality: Claude (full model, daily limit)
- Best free unlimited: Gemini (Flash model, no limits)
- Best free for occasional use: ChatGPT (GPT-4o mini, unlimited)
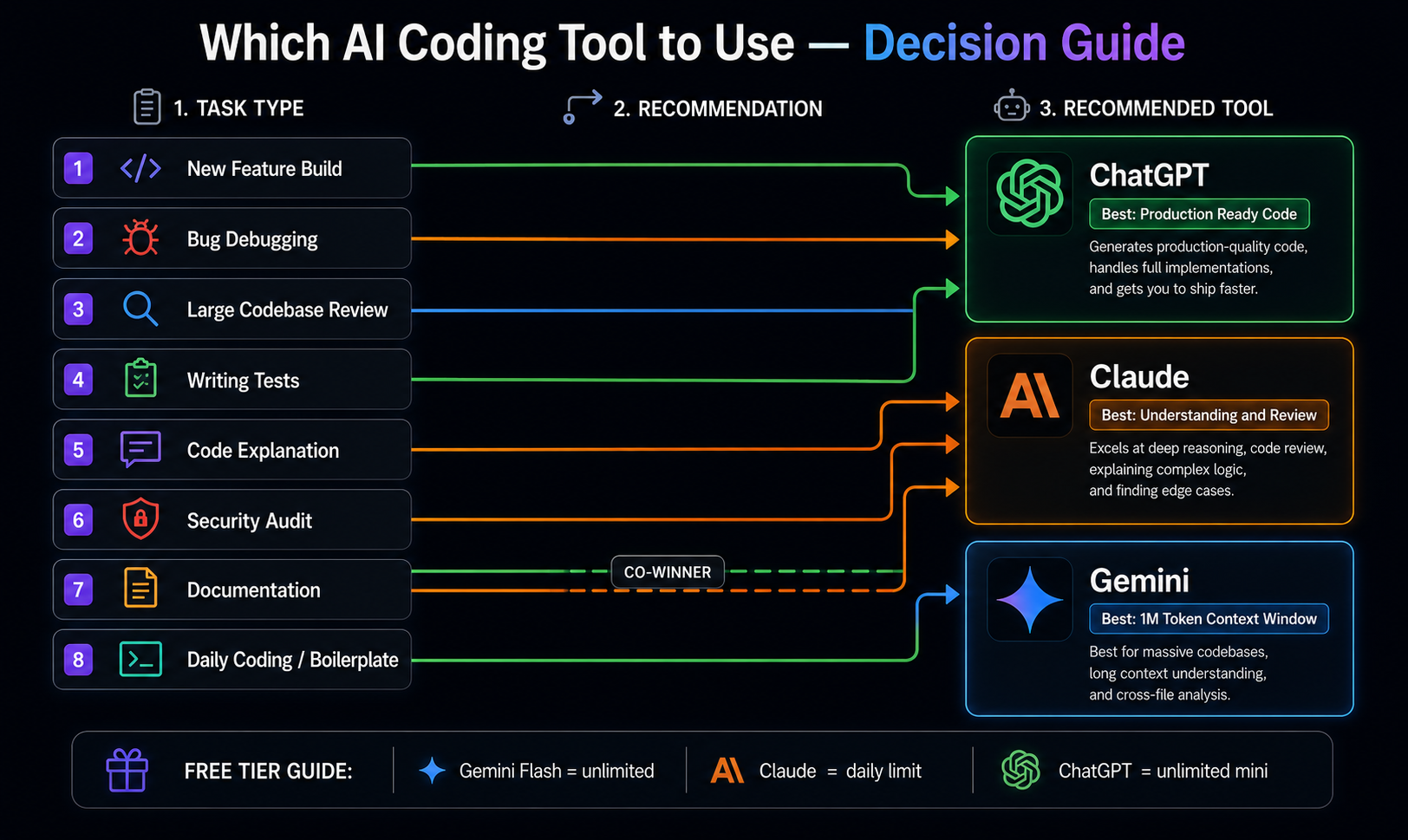
Which AI is Best for Your Specific Development Context
Best for Frontend Development (React, Vue, Angular)
ChatGPT leads for frontend work. The proactive addition of accessibility attributes, responsive design considerations, and performance optimizations on component generation consistently produces more complete frontend code. The knowledge of React patterns, hooks best practices, and common performance pitfalls is the deepest of the three models.
Claude is a very strong second — particularly for component refactoring and understanding complex state management patterns.
Best for Backend Development (Node.js, Python, Go)
ChatGPT again leads for backend production code, particularly for the completeness and security-consciousness of generated API code. The proactive addition of security headers, proper error handling middleware, and infrastructure considerations is consistently more thorough.
Claude is preferred for backend code review and security auditing — its vulnerability identification leads the three models by a meaningful margin.
Best for Data Science and ML (Python, Jupyter, pandas)
ChatGPT has the strongest Python data science fluency — the most accurate pandas operations, the best understanding of common ML workflow patterns, and the best performance when generating scikit-learn, TensorFlow, and PyTorch code.
Gemini has a useful advantage for Google-ecosystem ML work — TensorFlow, Vertex AI, and Google Colab workflows — reflecting its training origin.
Best for Full-Stack Development
Claude for understanding and reasoning about full-stack architectures. When the task is comprehending how a frontend, API, database, and background job system interact — and suggesting improvements to that interaction — Claude's architectural thinking and explanation quality are the strongest.
ChatGPT for generating full-stack code from scratch — the completeness of generated systems and proactive edge case handling produce more production-ready initial implementations.
Best for DevOps and Infrastructure (Docker, Kubernetes, CI/CD)
ChatGPT leads for DevOps and infrastructure code — the knowledge of Kubernetes configurations, Dockerfile best practices, and CI/CD pipeline patterns is the most practically current and correctly structured.
Best for Mobile Development (Swift, Kotlin, React Native)
ChatGPT for React Native, as expected from its general JavaScript strength. For native Swift and Kotlin, the capability gap between all three models is smaller — all three handle common patterns well, with ChatGPT having a slight edge on idiomatic native patterns.
Best for Learning and Understanding Code
Claude by a significant margin. When the goal is not just getting correct code but genuinely understanding why code works, what architectural patterns are being used, or how to approach a new language or framework — Claude's explanation quality and teaching ability produce outcomes that ChatGPT and Gemini cannot match consistently.
For students and developers actively learning, Claude's explanation quality makes it the most valuable educational coding tool available.
For more on Claude's broader capabilities and how it compares, read the Claude Fable 5 vs Claude Opus comparison.
The Optimal Developer Workflow — Using All Three
The developers getting the best results are not choosing one tool and ignoring the others. They are using each for what it does best.
The recommended multi-tool coding workflow:
New feature implementation → ChatGPT (production completeness, proactive edge cases)
Code review and security audit → Claude (vulnerability identification, architectural assessment)
Large codebase analysis → Gemini (1M context window, cross-file understanding)
Debugging complex issues → Claude (superior bug identification and explanation)
Learning new patterns or frameworks → Claude (explanation quality)
Daily syntax and boilerplate → Gemini Free (unlimited, no usage anxiety)
Test generation → ChatGPT (comprehensive coverage, proactive edge cases)
Documentation → Claude (writing quality advantage in technical prose)
This workflow is not as complicated as it sounds in practice. Most developers naturally develop a sense of which tool to reach for based on the type of task — and the free tiers of all three models make maintaining access to all three practically free.
Common Mistakes Developers Make with AI Coding Tools
Accepting generated code without review. All three models produce incorrect code with varying frequency — the best models just do it less often. Code review remains non-negotiable regardless of which AI generated it.
Not providing enough context. AI coding tools work significantly better when given context about the project architecture, existing patterns, constraints, and the specific problem being solved. A vague prompt produces a generic solution. A specific prompt with full context produces targeted, usable code.
Using one model for everything. The use-case differentiation between models is real and meaningful. Using ChatGPT for security review or Gemini for refactoring quality produces worse outcomes than using the right tool for each task.
Not iterating on outputs. The first AI-generated code is a starting point. The most effective AI coding workflows involve iteration — reviewing the initial output, providing specific feedback, and refining through conversation rather than accepting and moving on.
Over-relying on AI for architecture decisions. AI tools are excellent at implementing patterns but inconsistent at choosing between them for your specific context. Architectural decisions — technology choices, data model design, system boundaries — require your understanding of your specific constraints, team capabilities, and long-term maintenance considerations.
Expert Tips for Maximum Coding Efficiency
Tip 1 — Give AI your existing code patterns before asking for new code. Paste an example of existing code in your codebase — a similar function, your error handling pattern, your naming conventions — before asking for new code. AI models calibrate to your established patterns, producing code that fits your codebase rather than generic examples.
Tip 2 — Use Claude for code review even when you wrote the code yourself. Claude's security vulnerability identification and architectural assessment capabilities make it valuable as a pre-commit review step on code you wrote manually. The review catches issues that self-review misses because of familiarity bias.
Tip 3 — Use Gemini's context window for documentation. When needing to understand a large, unfamiliar codebase — onboarding to a new project, reviewing an open-source library, auditing inherited code — Gemini's ability to process the entire codebase in one context produces more accurate and complete understanding than any chunked analysis.
Tip 4 — Save your best prompts as templates. The prompts that consistently produce high-quality output for your specific development context — your language, your framework, your team's conventions — are worth saving and reusing. A library of 10 to 15 proven coding prompts dramatically reduces the iteration needed on common task types. For guidance on building effective prompts, read the complete prompt engineering guide.
Tip 5 — Ask AI to explain its own code. After receiving generated code, ask the model to explain the non-obvious parts, potential edge cases it handled, and any assumptions it made. This review step catches cases where the AI made incorrect assumptions about your requirements — before those assumptions cause production issues.
Key Takeaways
- ChatGPT leads for complete feature implementation, production readiness, proactive edge case handling, and multi-language fluency
- Claude leads for debugging, security review, code explanation, teaching, and refactoring quality
- Gemini leads for large codebase analysis thanks to its 1 million token context window, and offers the best unlimited free coding tier via Gemini 2 Flash
- The optimal developer workflow uses all three tools for different task types rather than committing exclusively to one
- Claude's free tier provides the highest quality ceiling per session; Gemini free provides unlimited access at strong quality; ChatGPT free provides unlimited access at moderate quality
- All three models produce incorrect code with varying frequency — code review is non-negotiable regardless of which model you use
- For learning and understanding code, Claude's explanation quality makes it the most valuable educational coding assistant available
Related articles
AI Tools
Claude Fable 5 vs Claude Opus: Which Anthropic Model Should You Use?
Claude Fable 5 vs Claude Opus — complete comparison of Anthropic's AI models in 2026. Benchmarks, capabilities, pricing, safety features, and which model is right for your use case.
AI Tools
12 Best AI Tools for YouTube Automation in 2026 (Complete Guide)
Discover the 12 best AI tools for YouTube automation in 2026. Ranked by category — scripts, voiceover, editing, thumbnails, SEO, Shorts, and analytics. Save 10+ hours per video.
Frequently Asked Questions
Which AI is best for coding in 2026? ChatGPT (GPT-5.5) leads for overall coding performance — particularly for complete feature implementation, production readiness, and multi-language fluency. Claude (Fable 5) leads for debugging, security review, and code explanation. Gemini 2 leads for large codebase analysis. For most developers, the best setup uses ChatGPT or Claude as a primary assistant and Gemini for large context tasks.
Is Claude better than ChatGPT for coding? Claude leads ChatGPT on specific coding tasks — debugging, security vulnerability identification, refactoring, and code explanation. ChatGPT leads on complete feature implementation, production readiness, and proactive edge case handling. Overall test results show Claude with more individual wins (4) but ChatGPT with slightly higher impact wins (feature implementation, test generation). Both are significantly better than any other AI coding tool at this tier.
Is Gemini good for coding? Gemini 2 is a capable coding assistant with one significant unique advantage — its 1 million token context window enables analysis of complete large codebases that other models must handle in fragments. For everyday coding tasks, Gemini performs well but typically below ChatGPT and Claude in production code quality and completeness. Gemini 2 Flash (completely free, unlimited) is the best free coding assistant for developers who need daily access without usage limits.
What is the best free AI coding tool? For unlimited access: Gemini 2 Flash (free, no limits, capable for daily coding tasks). For highest quality within limits: Claude free tier (full model quality, daily limit). For unlimited moderate quality: ChatGPT free (GPT-4o mini, unlimited). The best choice depends on whether you prioritize quality ceiling or unlimited access.
Can AI replace developers? No — and the framing misunderstands what AI coding tools actually do. They automate the implementation of patterns, handle boilerplate, suggest solutions to known problem types, and reduce syntax overhead. They do not replace the architectural judgment, requirement understanding, stakeholder communication, debugging of novel system-level issues, or contextual decision-making that define professional software development. The realistic framing: AI makes individual developers significantly more productive, not unnecessary.
Which AI is best for learning to code? Claude is the best AI for learning to code. Its explanation quality — the ability to explain not just what code does but why it works, what patterns it uses, and how to think about similar problems — produces genuine understanding rather than just working code. Students who use Claude as a learning tool rather than a code generator develop programming intuition significantly faster.
Does GitHub Copilot use these models? GitHub Copilot uses OpenAI models (GPT-4 family) as its primary code completion engine, with options to use Claude and Gemini models in some Copilot configurations. Copilot focuses on inline autocomplete within the IDE — a different interaction mode from the conversational coding assistance these three models provide through their chat interfaces.
Conclusion — The Right Tool for the Right Task
The Gemini vs ChatGPT vs Claude coding comparison does not have a single winner that every developer should use for every task.
ChatGPT is the strongest choice when you need complete, production-ready implementations with comprehensive edge case handling — particularly for new features, test suites, and multi-language tasks. The proactive completeness of ChatGPT's code generation is its defining advantage.
Claude is the strongest choice when you need to understand, improve, or verify existing code — debugging complex issues, identifying security vulnerabilities, understanding architectural patterns, and explaining code to yourself or others. Claude's reasoning depth applied to code produces results that ChatGPT matches in some areas and falls short in others.
Gemini is the strongest choice when you need to reason about a complete large codebase simultaneously — onboarding to a large project, auditing an unfamiliar system, or analyzing cross-file dependencies that smaller context windows force into fragments. The 1 million token context window is not a marginal advantage for these tasks. It is a fundamental capability difference.
The developers who will work most effectively with AI in 2026 are not those who found the best single tool. They are those who understand what each tool does distinctively well — and have built a workflow that deploys each one where it has the clearest advantage.
For more on AI tools and developer productivity, read the ChatGPT vs Claude vs Gemini complete comparison, the Claude Fable 5 vs Claude Opus comparison, the Gemini 2 vs GPT-5.5 full comparison, the best AI productivity tools guide, and the complete prompt engineering guide to get the most from every AI coding session.